-
[딥러닝의 이해 (1)] CRISP-DM, 데이터 전처리, 딥러닝 모델링 과정DL 2026. 2. 27. 22:48
- BDA 학회 정규학회원 11기로 활동하고 있으며, 정규 수업을 수강한 뒤 학습 내용 정리와 복습을 위해 글을 써봅니다.
- 본문에 포함된 그림 및 도식은 모두 제가 직접 PPT로 제작한 자료입니다.
- 실습 및 예시에 사용된 데이터는 강사님께서 제공하신 깃허브 저장소의 자료를 기반으로 하며, 글 하단에 출처를 표기했습니다.
- 실습 코드는 제 깃허브 링크를 참고하시면 됩니다.
BDAI(Big Data Artificial Intelligence)는 (사)한국빅데이터학회 산하 기관으로, 전국 70개 이상 대학에 네트워크를 가진 대학생 연합 빅데이터 분석 학회 및 실무 연계 학회이다. 전국 대학생, 대학원생, 직장인 대상으로 AI, 데이터 분석 실무 강의를 제공하고 있으며, 학술제, 공모전 및 해커톤 등 다양한 콘텐츠를 제공하고 있다. (현재 학회 명칭이 BDA에서 BDAI로 변경됨)
CRISP-DM
데이터 마이닝 및 데이터 과학 프로젝트를 위한 산업 간 표준 프로세스(Cross-Industry Standard Process for Data Mining)의 약자로, 데이터를 분석하여 유용한 지식을 얻기 위한 체계적이고 유연한 접근 방식이다.
강사님이 이건 꼭 외워야 한다며 엄청 강조하셨다. ADsP 자격증 공부를 하면서 들어봤던 용어였다.

전체 Process는 다음과 같다.
1. Business Understanding - 비즈니스 문제정의, 데이터분석 방향/목표 설정, 초기 가설 수립
2. Data Understanding - 원본 식별, 분석을 위한 구조 만들기, 데이터분석 EDA
3. Data Preparation - 모델링을 위한 데이터 구조 만들기
가장 중요한 단계로, 모든 셀은 값이 있어야 하며, 숫자여야 하며, 범위가 일치해야한다.
4. Modeling
5. Evaluation - 기술적 관점 평가, 비즈니스 관점 평가
6. Deployment - 모델 관리, AI 서비스 구축
이전까지는 구조 없이 문제부터 붙잡고 해결해 왔는데, 이 수업을 들은 후에는 전체 프로세스를 먼저 설계한 뒤 흐름대로 진행해보았다.
모델링 개요 (머신러닝 vs 딥러닝)
데이터 안에는 패턴이 담겨 있으며, 패턴이 없다면 그것은 노이즈다.
Model은 데이터로부터 패턴을 찾아, 수학식으로 정리해 놓은 것이다.
Modeling은 가능한 오차가 적은 모델을 만드는 과정이다.
딥러닝에 대해서 자세히 다뤄보기 전에, 머신러닝과 딥러닝은 어떤 차이가 있을까?
가장 중요한 차이는 Feature Engineering이다.
- 머신러닝은 새로운 feature를 추출하는 과정이 중요하다. 이 과정에서 사람이 직접 데이터를 살펴보면서 feature를 선택하게 된다.
- 딥러닝은 각 레이어를 통해 모델 안에서 자동으로 새로운 feature가 추출된다.
딥러닝 코드 구조

데이터 전처리 과정은 위의 표와 같이 나눌 수 있다.
데이터 전처리
1. 결측치 / 이상치 보간
결측치(Missing Value)와 이상치(Outlier)는 삭제하거나 보간한다. 시계열 데이터의 경우 보통 선형 보간/이화평
2. 가변수화
가변수화는 범주형 데이터를 숫자로 바꿔주는 과정이다. 이전까지는 프로젝트를 할 때 연속형 데이터만 사용해봐서 몰랐는데, 이번 수업을 통해 알게되었다.
One-Hot-Encoding으로 get_dummies() 함수를 사용한다.
예를 들어, 성별의 경우 남자는 1/ 여자는 0으로 표시하되 inplace=True를 사용해 Female 칼럼으로만 표현한다.
필요한 정보는 표현하되, 차원을 줄일 수 있다.

3. 스케일링
머신러닝의 경우, 거리 기반 알고리즘(kNN, K-menas, SVM 등)에만 스케일링을 해주고, 나머지 알고리즘에는 거의 사용하지 않는다.
딥러닝에서는 필수 조건이다. 대표적으로는 아래와 같이 2가지 방법이 있다.
1) Normalization (정규화)
: 모든 값의 범위를 0~1로 변환한다. MinMaxScaler() 함수 사용
데이터가 양수로 변환되기 때문에 로그 변환에는 유리하지만, 이상치에 민감합니다.

2) Standardization (표준화)
: 모든 값을 평균 = 0, 표준편차 = 1로 변환한다. StandardScaler() 함수 사용
데이터가 평균과 표준변차를 중심으로 정렬되기 때문에 안정적이나, 이상치에 민감합니다.

++
Box-Cox / Yeo-Johnson 변환은 분포의 치우짐을 줄이고 분산을 안정화해 정규성에 가깝게 만들기 위해 사용되는 변환으로 스케일링 전에 변환을 해주면 데이터가 더욱 정규성을 띄는 분포로 만들 수 있다.
1) Box-Cox 변환
: 비대칭적이고 비정상적인 분포를 가진 데이터를 정규 분포에 가까운 형태로 변환하는 데 단, 데이터가 양수일 때만 적용이 가능하다.
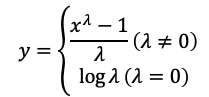
2) Yeo-Johnson 변환
: Box-Cox 변환의 단점을 보완한 변환이다. 음수 값이 있어도 처리할 수 있다.

모델링
1. 모델 구조
2. 컴파일
3. 학습
4. 학습 곡선
5. 예측 및 검증
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.metrics import * from sklearn.preprocessing import StandardScaler, MinMaxScaler강사님의 깃허브에 있는 데이터를 사용하였다.
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/advertising.csv' adv = pd.read_csv(path) adv.head()예측하고 싶은 값을 target으로 설정하고 x와 y를 지정해준다.
이후 x,y 데이터를 각각 학습/검증 데이터로 분류한다. random_state를 지정함으로써 실행할 때마다 항상 같은 방식으로 나뉜다는 것을 뜻한다. 즉, 실험 재현성(reproducibility)을 위해 필요하다.
target = 'Sales' x = adv.drop(target, axis=1) y = adv.loc[:, target] x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.2, random_state = 20)# ---------------- # 딥러닝 모델링 # ---------------- from keras.models import Sequential # Sequential(순차 모델 컨테이너 Seq 클래스) from keras.layers import Dense, Input # Input: 입력 텐서의 형상(shape)을 선언/ Dense: 완전연결측(=선형 결합+활성함수) from keras.backend import clear_session # 노트북에서 여러 번 모델을 만들 때 이전 그래프/메모리 잔여물을 지워줍니다. # 1) 전처리: Scaling scaler = MinMaxScaler() x_train = scaler.fit_transform(x_train) x_val = scaler.transform(x_val) # 2) 모델 선언 x_train.shape nfeatures = x_train.shape[1] #num of columns # 입력 특성(열) 개수를 꺼내 정수로 저장. nfeatures clear_session() #메모리 정리 model = Sequential( [Input(shape =(nfeatures,)), # input으로 nfeatures(3)개를 받겠다 Dense(1)] ) # layer 수 = 1 model.summary() # 3) 컴파일 model. compile(optimizer='adam', loss='mse') # 4) 학습 model.fit(x_train, y_train) # 5) 예측 pred = model.predict(x_val) # 6) 검증 print(f'RMSE : {root_mean_squared_error(y_val, pred)}') print(f'MAE : {mean_absolute_error(y_val, pred)}') print(f'MAPE : {mean_absolute_percentage_error(y_val, pred)}')코드 중간에 model.summary()를 실행하면 아래와 같이 모델 구조와 파라미터 정보를 출력할 수 있다.
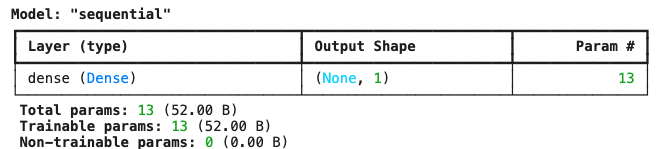
단순 회귀 모델의 성능 지표는 아래와 같고, 각 지표의 의미와 해석은 다음 글에서 정리하겠다.
