-
[BDA학회 11기] 딥러닝의 이해 1주차공부 2025. 9. 22. 22:57

1주차 블로그 챌린지 BDA 학회란?
BDA는 (사)한국빅데이터학회 산하 기관으로, 전국 70개 이상 대학에 네트워크를 가진 대학생 연합 빅데이터 분석 학회 및 실무 연계 학회이다. 전국 대학생, 대학원생, 직장인 대상으로 AI, 데이터 분석 실무 강의를 제공하고 있으며, 학술제, 공모전 및 해커톤 등 다양한 콘텐츠를 제공하고 있다.
BDA 학회를 선택한 이유
학부 전공 수업과 ADsP 자격증 공부를 통해 머신러닝/딥러닝의 기초적인 지식은 익혔으나, 구현을 제대로 해본 적이 없다. 나는 체계적인 수업이나 책을 통해 공부를 하는 것에 익숙해져있어 혼자서 서치하면서 코드를 구현해보는 것에 대한 뭔지 모를 불편함이 있다. 어디서부터 어떻게 코드를 짜봐야할지 모르겠어서 관련된 활동을 찾아보던 와중 BDA학회(대학생 학회)를 알게되었다.
BDA 수업은 일주일에 1시간씩 진행되는 실시간 줌수업이다. 체계적인 커리큘럼과 강사님들의 이력을 보고 전문적이라고 느꼈고, 일주일에 1시간씩이라는 점이 부담스럽지 않게 다가왔다. 실시간 줌수업이라 수업에 더욱 집중할 수 있을 것이며 매주 복습과제가 있어 공부를 소홀히 하지 않을 것 같아서 신청하게 되었다. 또, 수업뿐만 아니라 원데이 클래스, 공모전 등 다양한 활동을 지속적으로 하는 것으로 보아 활발한 학회라는 점이 가장 마음에 들었다.
BDA 수업에서 가장 기대되는 점
뭐든 끝까지 끈기있게 하는 것이 가장 중요한데, 나는 항상 쉽지 않았다. 매주 수업 내용도 복습할겸 학습기록을 남겨놓고 싶어서 블로그 챌린지를 신청하게되었다. 10주차동안 과제, 블로그 등 강제성을 부여해 끝까지 완주하는게 가장 큰 목표다. 꾸준한 복습과 추가적인 공부를 하면서 이 수업이 끝나는 날의 나의 역량을 기대해봐야겠다. 복학하기 전 이번 학기 최선을 다해 공부할 계획이다.
1주차 내용 리뷰
CRISP-DM
데이터 마이닝 및 데이터 과학 프로젝트를 위한 산업 간 표준 프로세스(Cross-Industry Standard Process for Data Mining)의 약자로, 데이터를 분석하여 유용한 지식을 얻기 위한 체계적이고 유연한 접근 방식이다.
강사님이 이건 꼭 외워야 한다며 엄청 강조하셨다. ADsP 자격증 공부를 하면서 들어봤던 용어였다.
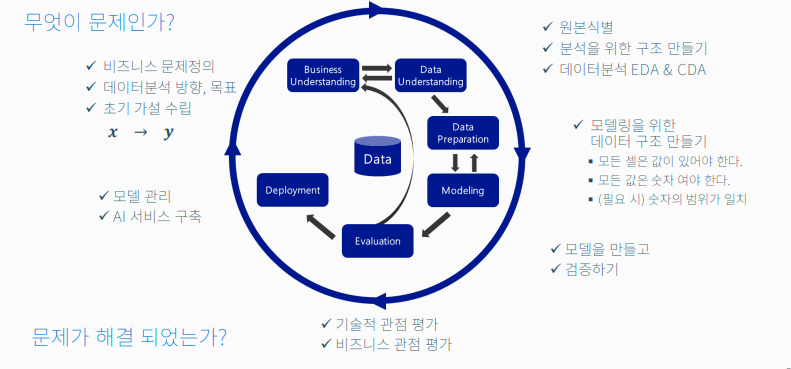
출처: BDA 딥러닝의 이해(1) 1주차 수업자료 1. Business Understanding
2. Data Understanding
3. Data Preparation
가장 중요한 단계로, 모든 셀은 값이 있어야 하며, 숫자여야 하며, 범위가 일치해야한다.
4. Modeling
5. Evaluation
6. Deployment
총 6단계로 이루어져있다.
데이터 안에는 패턴이 담겨 있으며, 패턴이 없다면 그것은 노이즈다.
Model은 데이터로부터 패턴을 찾아, 수학식으로 정리해 놓은 것이다.
Modeling은 가능한한 오차가 적은 모델을 만드는 과정이다.
모델의 성능은 오차(error)를 통해 계산된다.
모델링은 train error를 최소화하는 모델을 생성하는 과정이고,
모델 튜닝은 validation error를 최소화하는 모델을 선정하는 것이다.
모델의 평가 지표는 다음과 같다.

출처: BDA 딥러닝의 이해(1) 1주차 수업자료 다음은 머신러닝과 딥러닝의 코드 구조 차이를 도식화한 것이다.
가장 큰 차이는 스케일링과 컴파일이다.
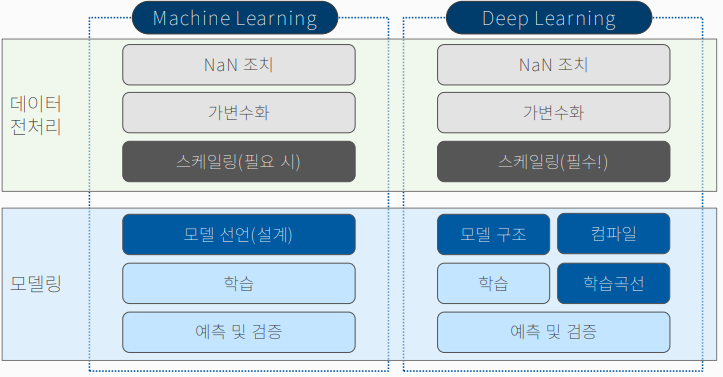
출처: BDA 딥러닝의 이해(1) 1주차 수업자료
앞으로 코드 위주로 리뷰하면서 내가 생각하기에 자주 쓰이는/중요한 문법 위주로 작성할 예정이다.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.metrics import * from sklearn.preprocessing import StandardScaler, MinMaxScaler# 1) 데이터 준비 path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/advertising.csv' adv = pd.read_csv(path) adv.head() target = 'Sales' x = adv.drop(target, axis=1) y = adv.loc[:, target]데이터는 강사님 깃허브에 있는 데이터를 사용해서 진행한다.
.head(): 칼럼명과 상위 5개 행(기본값)을 불러와 데이터 미리보기
x = adv.drop(target, axis=1): target을 제외한 칼럼만 추출, axis=1은 칼럼에서 읽는다는 뜻이다. (axis=0은 행)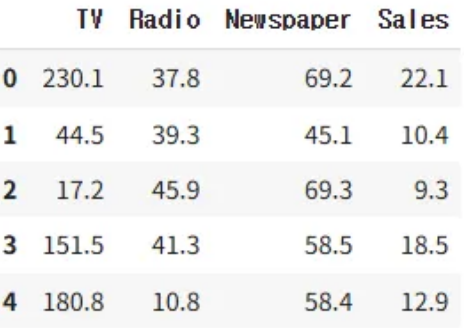
출처: BDA 딥러닝의 이해(1) 1주차 수업자료 # 2) 가변수화(.head()로 값들이 범주형일 때만 실행!) # 3) 데이터 분할 x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.2, random_state = 20)가변수화는 범주형 데이터의 경우 숫자로 바꿔주는 것을 의미하는데, 이번 데이터는 모두 숫자로 이루어져 있어 실행하지 않는다. (실행하는 코드는 다음 주차에서 설명하겠다.)
데이터 분할은 데이터를 훈련/검증 데이터로 구분하는 과정이다. 훈련 데이터는 모델을 학습하기 위해 사용되는 데이터이고, 검증 데이터는 훈련 데이터로 학습된 모델을 검증하는 역할이다.
test_size=.2로 정한 것은 훈련/검증 데이터를 80%/20%로 나눈 것이다.
train_test_split은 데이터를 무작위로 섞어서 나누는데, random_state을 지정함으로써 실행할 때마다 항상 같은 방식으로 나뉜다는 것을 뜻한다. 즉, 실험 재현성(reproducibility)을 위해 필요하다.## 2. ML(선형회귀) # 선형회귀 알고리즘을 불러 온다. from sklearn.linear_model import LinearRegression # 모델 선언 model = LinearRegression() # 학습 model.fit(x_train, y_train) # 예측 pred = model.predict(x_val) # 검증 print(f'RMSE : {root_mean_squared_error(y_val, pred)}') print(f'MAE : {mean_absolute_error(y_val, pred)}') print(f'MAPE : {mean_absolute_percentage_error(y_val, pred)}')## 3. 딥러닝 모델링 from keras.models import Sequential # Sequential(순차 모델 컨테이너 Seq 클래스) from keras.layers import Dense, Input # Input: 입력 텐서의 형상(shape)을 선언/ Dense: 완전연결측(=선형 결합+활성함수) from keras.backend import clear_session # 노트북에서 여러 번 모델을 만들 때 이전 그래프/메모리 잔여물을 지워줍니다. # 1) 전처리: Scaling scaler = MinMaxScaler() x_train = scaler.fit_transform(x_train) x_val = scaler.transform(x_val) # 2) 모델 선언 x_train.shape nfeatures = x_train.shape[1] #num of columns # 입력 특성(열) 개수를 꺼내 정수로 저장. nfeatures모델에 데이터를 입력하기 위해 입력되는 숫자의 범위 및 분포를 다른 변수와 동일하게 해주어야 한다.
이 과정이 바로 스케일링(Scaling)이다. 방법은 2가지로, Normalization(정규화)와 Standardization(표준화)이다.
1. Normalization(정규화): 모든 값의 범위를 0~1로 변환
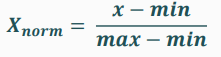
출처: BDA 딥러닝의 이해(1) 1주차 수업자료 2. Standardization(표준화): 모든 값을 평균=0, 표준편차=1로 변환
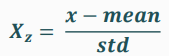
출처: BDA 딥러닝의 이해(1) 1주차 수업자료 코드로 돌아가보면, MinMaxScaler()는 정규화와 같은 것으로 어떤 스케일러를 사용할 것인지 정하는 것이다.
x_train = scaler.fit_transform(x_train)
x_val = scaler.transform(x_val)여기서 .fit은 train set에만 해준 것을 알 수 있다. .fit은 데이터를 보고 스케일링에 필요한 통계값(min, max, mean, std 등)을 계산해서 저장하는데 훈련 데이터에만 해주어야 한다. 검증 데이터에서 또 한번 이루어지게 되면 통계값들이 바뀌기 때문이다.
## 4. 모델 구조 # 메모리 정리 # Sequential 타입 모델 선언 # 모델 요약 # 컴파일 # 학습 # 예측 # 검증딥러닝 모델 구조에 대해서는 다음 주차 블로그에서 다루겠다. 수업 때 그냥 코드 실행만 해보기도 했고, 다음 주차에서부터 코드 하나하나 다루니 다음 블로그에서 확인해주세요!
'공부' 카테고리의 다른 글
[BDA 학회 11기] 딥러닝의 이해 4주차 (0) 2025.10.13 [BDA 학회 11기] 딥러닝의 이해 3주차 (0) 2025.10.06 [BDA학회 11기] 딥러닝의 이해 2주차 (0) 2025.09.24 45회 ADsP 일주일 벼락치기 시험 후기 (전공자편) (6) 2025.06.06