-
[BDA 학회 11기] 딥러닝의 이해 3주차공부 2025. 10. 6. 20:35

3주차 블로그 챌린지 3주차 내용 리뷰
모델 구조 Dense
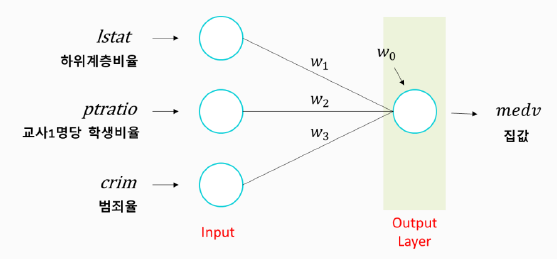
출처: BDA 딥러닝의 이해(1) 3주차 수업자료 - Input: Input ( shape = ( , ) )
- 분석 단위에 대한 shape
- 1차원: (feature 수, )
- 2차원: (rows, columns)
- 분석 단위에 대한 shape
- Output: Dense( )
- 예측 결과가 1개 변수
# 메모리 정리 clear_session() # Sequential 타입 model = Sequential([Input(shape = (nfeatures, )), Dense(1)]) # 모델 요약 model.summary()nfeatures는 입력 노드의 수로 위의 그림에서는 값이 3이다.
Dense(1)은 출력 노드의 수로 예측 결과는 1개 변수이다.
출처: BDA 딥러닝의 이해(1) 3주차 수업자료 컴파일
- 선언된 모델에 대해 몇 가지를 설정한 후 컴퓨터가 이해할 수 있는 형태로 변환하는 작업
- 머신러닝과 달리 딥러닝 과정에서 필수적인 단계
model.compile(optimizer = Adam(learning_rate = 0.1), loss = 'mse')1. optimizer: 오차를 최소화 하도록 가중치를 업데이트하는 역할
- Adam: 최근 딥러닝에서 가장 성능이 좋은 optimizer로 평가됨.
- learning_rate: 업데이트 할 비율
2. loss function(오차 함수): 오차 계산을 어떻게 할 것인가
- 회귀 모델: mse
- 분류 모델: cross entropy
출처: BDA 딥러닝의 이해(1) 3주차 수업자료 가중치를 업데이트할 때 학습률이 너무 작으면 최소값에 도달하지 못할 수 있고, 너무 크면 loss가 들쑥날쑥하게 된다.
학습률은 하이퍼파라미터로 적절한 값을 지정해줘야 한다.
학습
history = model.fit(x_train, y_train, epochs=20, validation_split=0.2).historyepoch=20: 주어진 train set을 20번 반복 학습한다는 것이다.
validation_split = 0.2: train 데이터에서 20%를 검증셋으로 분리한다.
.history: 학습을 수행하는 과정 중 가중치가 업데이트 되면서 학습 시 계산된 오차를 기록한다.학습 곡선
각 epoch마다 train error와 val error가 어떻게 줄어들고 있는지 확인하기 위한 곡선이다.
바람직한 학습 곡선은 1. 초기 epoch에서는 오차가 크게 줄고 2. 오차 하락이 꺾이면서 3. 점차 완만해지는 것이다.

출처: BDA 딥러닝의 이해(1) 3주차 수업자료 다음은 바람직하지 않은 학습 곡선이다.
Case1. 학습이 덜 된 곡선
- epoch 수를 늘리기
- learning rate를 크게

출처: BDA 딥러닝의 이해(1) 3주차 수업자료 Case2. train error가 불규칙적인 곡선
- learning rate를 작게
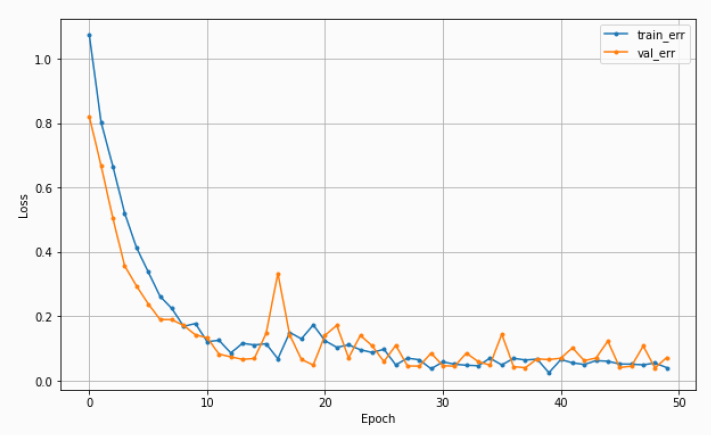
출처: BDA 딥러닝의 이해(1) 3주차 수업자료 Case 3. 과적합
: train error는 줄어드는데, validation error가 어느 순간부터 커지기 시작한다.
- epoch 수 줄이기

출처: BDA 딥러닝의 이해(1) 3주차 수업자료 이번 주차에는 모델 구조를 중심으로 컴파일, 학습하는 과정을 살펴봤다. 다음 주차에는 모델의 은닉층(hidden layer)에 대해서 살펴보겠다.
BDA 활동 및 수업에 대한 리뷰
지금까지 3주 동안 빅데이터 분석 학회(BDA)의 수업을 들었다. 강사님의 친절한 설명과 체계적인 커리큘럼 덕분에 어려운 내용도 쉽게 이해할 수 있었고, 수업을 듣는 과정 자체가 재미있었다. 매주 주어지는 복습 과제는 난이도가 부담스럽지 않아 꾸준히 복습하는 데 도움이 되었고, 동시에 조금 더 어려운 과제를 해보고 싶다는 도전 의욕도 생겼다.
현재 휴학 중이라 총 다섯 개의 수업을 함께 듣고 있는데, 매주 과제를 수행하며 꽤 많은 시간을 투자하고 있다. 하지만 그만큼 학습 효과가 커서 매우 의미 있게 시간을 보내고 있다. 무엇보다 BDA 학회는 단순히 수업만 진행하는 것이 아니라 원데이 클래스, 블로그 챌린지 등 다양한 프로그램을 체계적으로 운영하고 있다. 앞으로 관심 있는 주제나 시간이 맞는 프로그램이 있다면 꼭 참여해보고 싶다.
'공부' 카테고리의 다른 글
[BDA 학회 11기] 딥러닝의 이해 4주차 (0) 2025.10.13 [BDA학회 11기] 딥러닝의 이해 2주차 (0) 2025.09.24 [BDA학회 11기] 딥러닝의 이해 1주차 (0) 2025.09.22 45회 ADsP 일주일 벼락치기 시험 후기 (전공자편) (6) 2025.06.06 - Input: Input ( shape = ( , ) )