-
[BDA학회 11기] 딥러닝의 이해 2주차공부 2025. 9. 24. 15:44

2주차 블로그 챌린지 BDA학회(빅데이터 분석 학회)에 관심있는 분들은 인스타(@official.bdaa)나 웹사이트(https://bdaprogram.oopy.io/) 들어가보세요!
사진에 링크 걸어뒀습니당
인스타그램 팔로우 인증 
BDA 블로그 이웃 인증 2주차 내용 리뷰
딥러닝 모델이 학습되는 과정
학습 단계
1. 가중치에 (초기)값을 할당한다.
2. (예측)결과를 뽑느다.
3. 오차를 계산한다. (loss function) (오차 = 실제 값 - 예측 값)
4. 오차를 줄이는 방법으로 가중치를 조정
- Optimizer: GD, Adam ... (조정 비율: learning rate)
5. 다시 1단계로 올라가 반복한다.
- Max iteration에 도달. 오차의 변동이 (거의) 없으면 끝.
- 전체 데이터를 적절히 나눠서(mini_batch) 반복: batch_size
- 전체 데이터를 몇 번 반복 학습할 지 결정: epoch
학습한다는 것은 "오차를 최소화하는 파라미터(가중치) 값을 찾는다"는 의미다.학습하는 과정은 다음 그림과 같다. 초기에 가중치를 할당한 후 학습률을 조정하며 global loss minimum값을 찾아 가는 과정이다.

출처: https://doug.tistory.com/44 딥러닝의 기본적인 개념 정리부터 하고 가겠다.
- epoch: 하나의 단위로, 모델이 학습 데이터셋 전체에 대한 학습을 완료한 상태
- 1에폭은 학습에서 훈련 데이터를 모두 소진했을 때의 횟수
- 주어진 train set을 몇 번 반복 학습할 지 결정
- lr(학습률): 다음 학습에서 나아가는 정도 즉, 조정 비율
이 두 파라미터는 하이퍼파라미터이다.
하이퍼파라미터는 모델 학습 시, 사람이 정해주어야 하는 옵션이다. 다양한 값으로 시도해보고, 검증 평가를 통해 최적의 값을 찾는 과정을 하이퍼파라미터 튜닝이라고한다.
- mini batch: 전체 데이터 셋을 몇 개의 데이터 셋으로 나누었을 때, 그 작은 데이터 셋 뭉치
- batch_size: 하나의 미니 배치에 넘겨주는 데이터 갯수, 즉 한번의 배치마다 주는 샘플의 size (기본값: 32)
- iteration: 하나의 미니 배치를 학습할 때 1 iteration이라고 한다. 즉, 미니 배치 갯수 = 이터레이션 수
위의 용어들이 처음에 배울 때는 엄청 헷갈렸는데 그림으로 보면 조금 더 이해가 쉬울 것 같아 그려봤다.
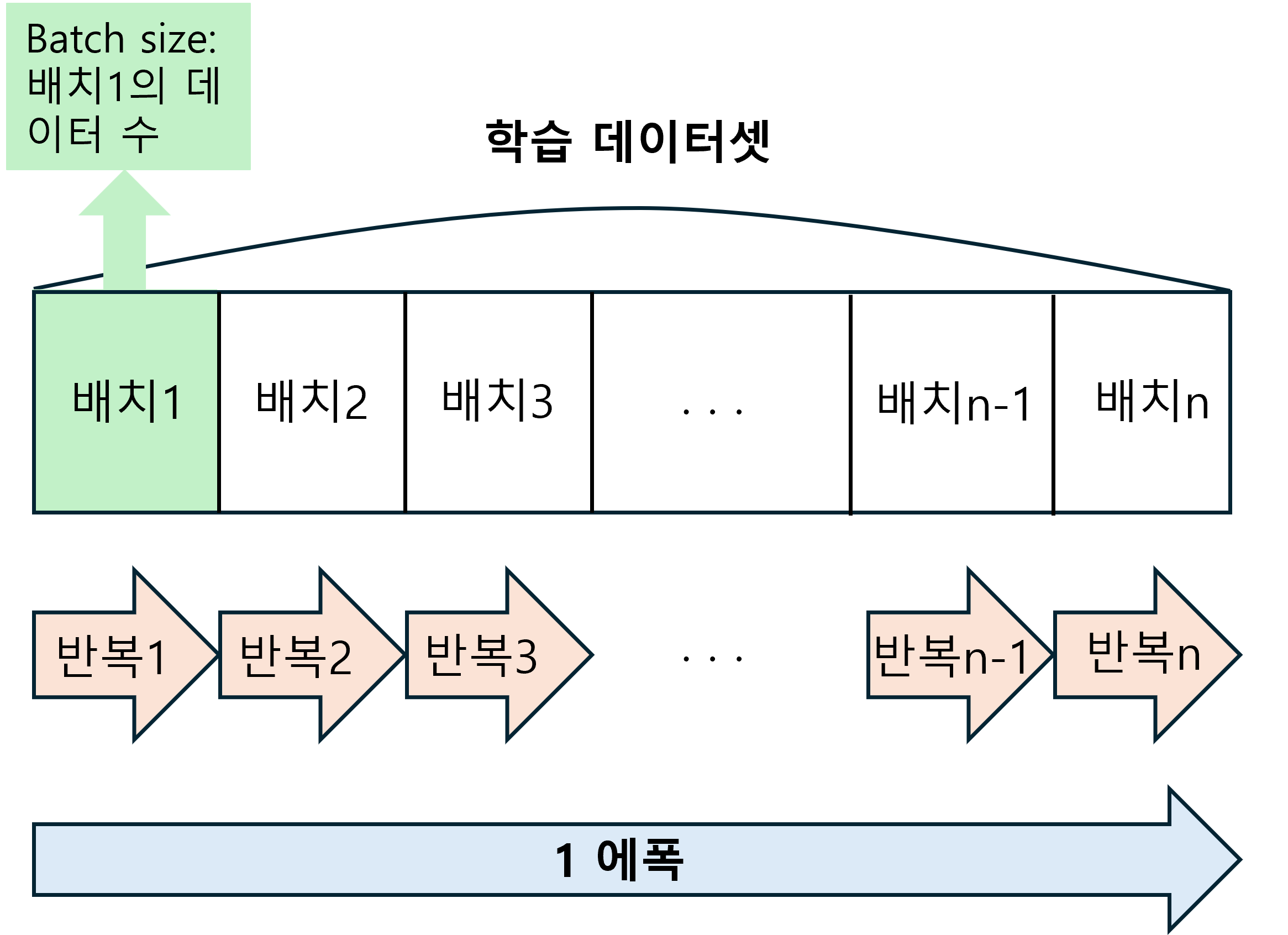
출처: https://doug.tistory.com/44
아래 코드는 그래프를 시각화하기 위한 코드로 자세히 살펴보진 않을 것이다.
def dl_visualize(ep, lr): clear_session() model = Sequential([ Dense(1, input_shape=(1,)) ]) model.compile(loss='mse', optimizer=Adam(learning_rate=lr)) # 수정된 부분: .weights.h5로 파일 경로 확장자 변경 mcp = ModelCheckpoint(filepath='/content/epoch_{epoch:02d}.weights.h5', monitor='val_loss', save_best_only=False, save_weights_only=True) history = model.fit(x_train_s, y_train_s, verbose=0, epochs=ep, callbacks=[mcp]).history coef, intercept = [], [] for i in range(ep): file = f'/content/epoch_{i+1:02d}.weights.h5' model.load_weights(file) coef.append(np.array(model.weights[0])[0,0]) intercept.append(np.array(model.weights[1])[0]) plt.figure(figsize=(20, 8)) plt.subplot(1, 2, 1) sns.scatterplot(x=x_train_s.reshape(-1,), y=y_train_s, alpha=.5) plt.grid() plt.xlabel('lstat') for i in range(ep): x = np.linspace(0, 1, 10) y = coef[i] * x + intercept[i] plt.plot(x, y, 'r--', linewidth = .5) v = 1.005 plt.text(v, coef[i] * v + intercept[i], f'ep:{i+1}', color='r') plt.subplot(1, 2, 2) plt.plot(range(1, ep+1), history['loss'], label='train_err', marker='.') plt.ylabel('Loss') plt.xlabel('Epoch') plt.legend() plt.grid() plt.show()
다음은 학습률과 에폭 수를 조정하면서 어떻게 학습이 이루어지는지 살펴볼 것이다.
먼저, 학습률을 고정하고 에폭 수를 조정하면서 결과를 비교해볼 것이다.
1) ep = 5: 손실 감소가 시작되지만 underfitting 상태이다. 즉, 데이터 분포를 잘 설명하지 못한다.
dl_visualize(ep = 5, lr = 0.01)
epoch = 5 2) ep = 10: 손실이 급격하게 줄어들고, 데이터 패턴을 어느 정도 학습했다고 볼 수 있다.
dl_visualize(ep = 10, lr = 0.01)
epoch = 10 3) ep = 15: 손실이 안정적으로 수렴하며, 회귀선이 데이터 분포와 잘 맞는다.
dl_visualize(ep = 15, lr = 0.01)
epoch = 15 Epoch 증가할수록 회귀선이 점점 데이터 분포와 잘 맞다. 또한, 손실곡선이 더 길게 이어지며 낮아지는 것을 확인할 수 있다. 이는 개선폭이 크지 않고 점차 완만해지면서 안정적인 상태라는 의미다.
다음은 epoch 수를 고정하고, 학습률을 조정해볼 것이다.
1) lr = 0.001: 학습이 매우 느려 손실이 크고, underfitting의 경향이 있다. (데이터 분포 설명 X)
dl_visualize(ep = 20, lr = 0.001)
학습률 = 0.001 2) lr = 0.01: 손실이 빠르게 줄고, 회귀선이 데이터 분포와 잘 맞는다. (가장 이상적인)
dl_visualize(ep = 20, lr = 0.01)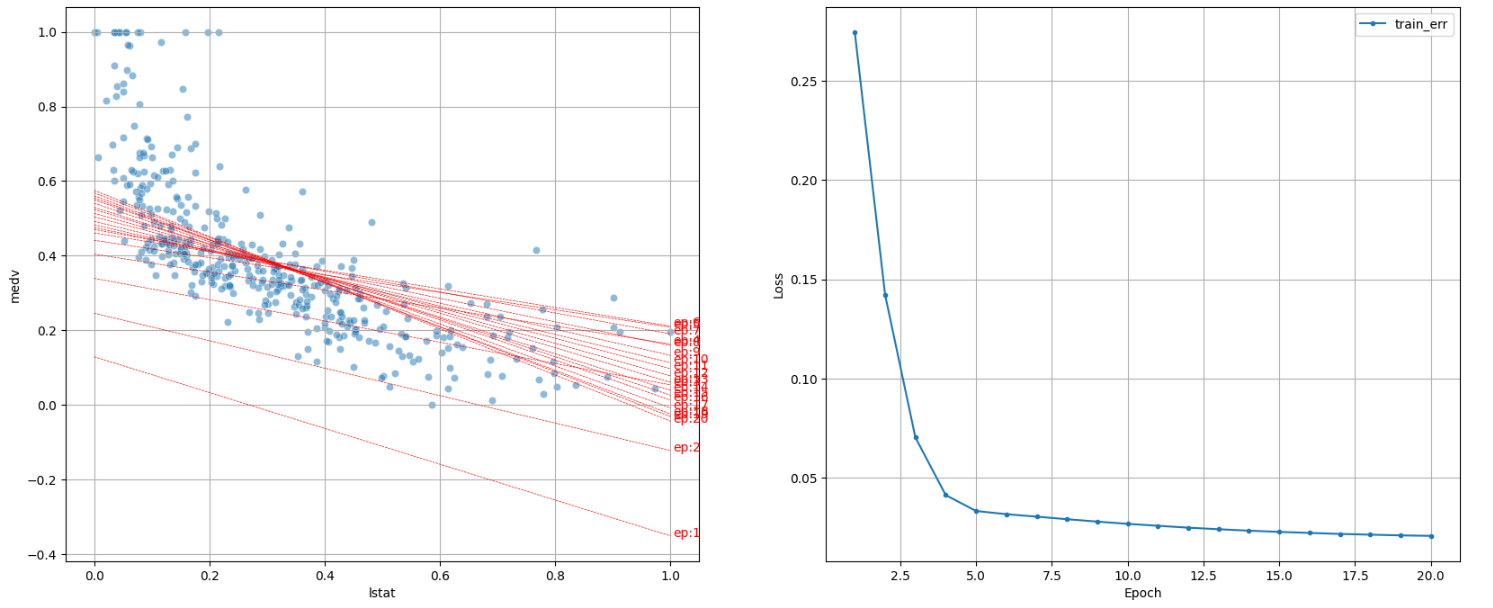
학습률 = 0.01 3) lr = 0.1: 학습 속도가 빨라 데이터 분포에 빠르게 근접하지만, 불안정할 수 있다.
dl_visualize(ep = 20, lr = 0.1)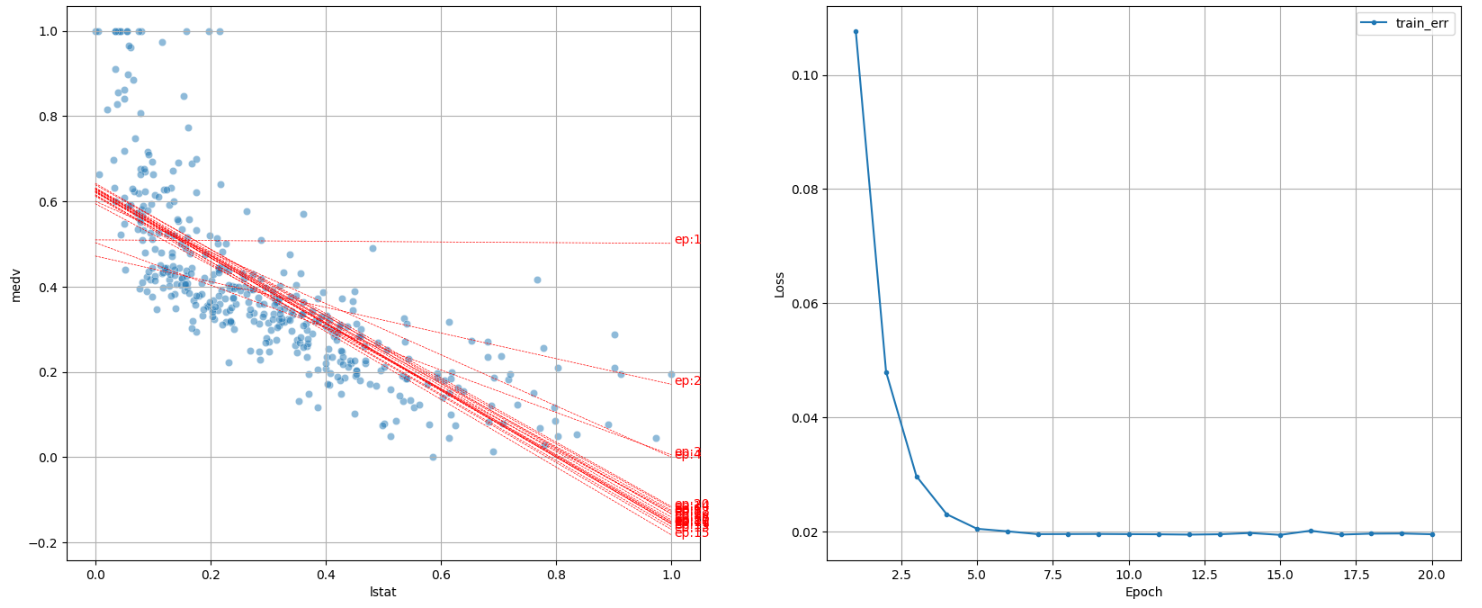
학습률 = 0.1 학습률은 너무 작으면 학습이 거의 안 되고, 너무 크면 불안정할 수 있다.
이번 주차는 하이퍼파라미터에 따른 그래프를 살펴보았다. 1주차 마지막에 언급했던 모델 구조는 3주차의 핵심 내용으로 더 자세히 다룰 예정이니 3주차 블로그를 기대해주시면 감사하겠습니다!
'공부' 카테고리의 다른 글
[BDA 학회 11기] 딥러닝의 이해 4주차 (0) 2025.10.13 [BDA 학회 11기] 딥러닝의 이해 3주차 (0) 2025.10.06 [BDA학회 11기] 딥러닝의 이해 1주차 (0) 2025.09.22 45회 ADsP 일주일 벼락치기 시험 후기 (전공자편) (6) 2025.06.06 - epoch: 하나의 단위로, 모델이 학습 데이터셋 전체에 대한 학습을 완료한 상태